Why AI Agents Fail in Production: The 89% Failure Rate Problem

A conference room. Q1 planning. Someone pulls up a vendor demo: an AI agent handles customer support tickets, updates the CRM, and closes the loop with the client. Autonomously. Under two minutes.
You’ve seen this demo. Maybe several times from several vendors.
Now picture what happened when your team tried to build something similar. The agent routed 40% of tickets to the wrong department. It treated “customer” in the support database the same as “customer” in the billing system. It wrote perfect responses that escalated instead of resolving issues.
This gap between demo and deployment defines the AI agent crisis in 2026. Industry research reveals that only 11% of AI agents ever make it to production. The other 89% die in proof-of-concept purgatory, trapped between executive enthusiasm and engineering reality.
Understanding why agents fail is the first step toward building ones that actually work.
The Production Gap: What the Data Shows
The numbers tell a stark story. While 67% of large enterprises now run some form of autonomous AI agent in production as of early 2026, this figure masks a deeper problem. Most deployments remain narrowly scoped, heavily supervised, and far from the autonomous operation that vendors promise.
Research from multiple industry sources points to consistent failure patterns. Agents struggle with three core challenges: reliability in real-world conditions, integration with existing systems, and governance at scale.
The reliability problem deserves particular attention. In controlled demos, agents operate on curated datasets with clear boundaries. Production environments present messy reality: incomplete data, ambiguous user intent, edge cases that nobody anticipated. An agent that handles 95% of requests in testing may crash to 60% reliability when deployed, simply because real-world data differs from training data in ways that only emerge after deployment.
Integration presents equally daunting obstacles. Enterprises run on complex software ecosystems: legacy databases, custom APIs, permission systems built over decades. An AI agent must navigate this labyrinth while maintaining security and compliance. The technical complexity of these integrations explains why many agents never progress beyond the prototype stage.
Governance rounds out the triad of challenges. When an autonomous agent makes a mistake, who bears responsibility? How do you audit its decisions? What happens when it behaves in ways you didn’t expect? These questions lack simple answers, and their complexity causes organizations to pause deployments indefinitely.
Why Traditional Approaches Don’t Work
The instinct when agents fail is to add more safeguards. More human oversight. More rules. More constraints. This approach often makes things worse.
Traditional software relies on explicit instructions. Developers write code that handles specific scenarios. When edge cases emerge, developers add more code. This iterative approach works for deterministic systems but collapses under the weight of AI agent complexity.
Agent behavior emerges from the interaction between base models, tool definitions, and environmental feedback. Adding rules to constrain one failure mode often creates three new failure modes in other areas. The system becomes a fragile patchwork of special cases that nobody fully understands.
The fundamental issue is that agentic AI requires a different development paradigm. Rather than specifying exact behaviors, developers must specify goals, constraints, and success criteria. The agent then determines how to achieve those goals. This shift from imperative to declarative design requires new skills that most engineering teams lack.
Organizations that succeed with production agents invest heavily in evaluation frameworks, not just agent frameworks. They build robust systems for testing agents against diverse scenarios before deployment. They accept that agents will make mistakes and design systems that detect and recover from those mistakes gracefully.
The Foundation Problem: Infrastructure That Can’t Support Agents
Before discussing agent architecture, organizations must confront an uncomfortable truth: most enterprise infrastructure wasn’t designed for autonomous agents.
Consider the typical API. It responds to requests with data. An agent sends requests, receives responses, and determines next steps. This works when APIs return clean, consistent data. Reality intrudes: APIs that timeout, return partial data, expose different schemas to different users, or change without warning.
Production agents require infrastructure that most enterprises lack. They need reliable access to data across systems. They need consistent authentication and authorization. They need monitoring that tracks not just system health but decision quality.
Google Cloud Consulting’s research on enterprise agentic AI transformation highlights a common pattern: organizations rush to deploy agents on unstable foundations, then blame the agents when things go wrong. The technology fails not because agents are inherently unreliable, but because they’re built on infrastructure that can’t support their operation.
Fixing this foundation isn’t glamorous. It involves standardizing APIs, improving data quality, establishing robust authentication flows, and building comprehensive monitoring. These tasks feel mundane compared to the excitement of deploying AI agents, but they’re essential.
Architecture Patterns That Work
Despite the challenges, some organizations have cracked the code on production agents. Their approaches offer lessons for the rest of us.
The most successful pattern involves starting narrow and expanding gradually. Rather than building a general-purpose agent that handles everything, teams build agents that excel at specific tasks. A customer support agent might start by handling password reset requests only. Once that works reliably, it expands to address changes, then billing questions, then complex troubleshooting.
This incremental approach allows teams to identify and fix problems before they cascade. Each expansion brings new failure modes, but the baseline remains stable. Organizations avoid the common trap of building sophisticated agents that fail in sophisticated ways.
Another effective pattern involves human-in-the-loop architectures that don’t slow things down. Rather than requiring human approval for every action, successful agents operate autonomously within defined boundaries. When they encounter situations outside those boundaries, they escalate gracefully. The key is defining those boundaries clearly and building robust detection of boundary crossings.
Successful agents also embrace uncertainty. Rather than pretending they understand requests they don’t, they ask clarifying questions. This humility frustrates users who want instant answers, but it produces more reliable outcomes than confident wrong responses.
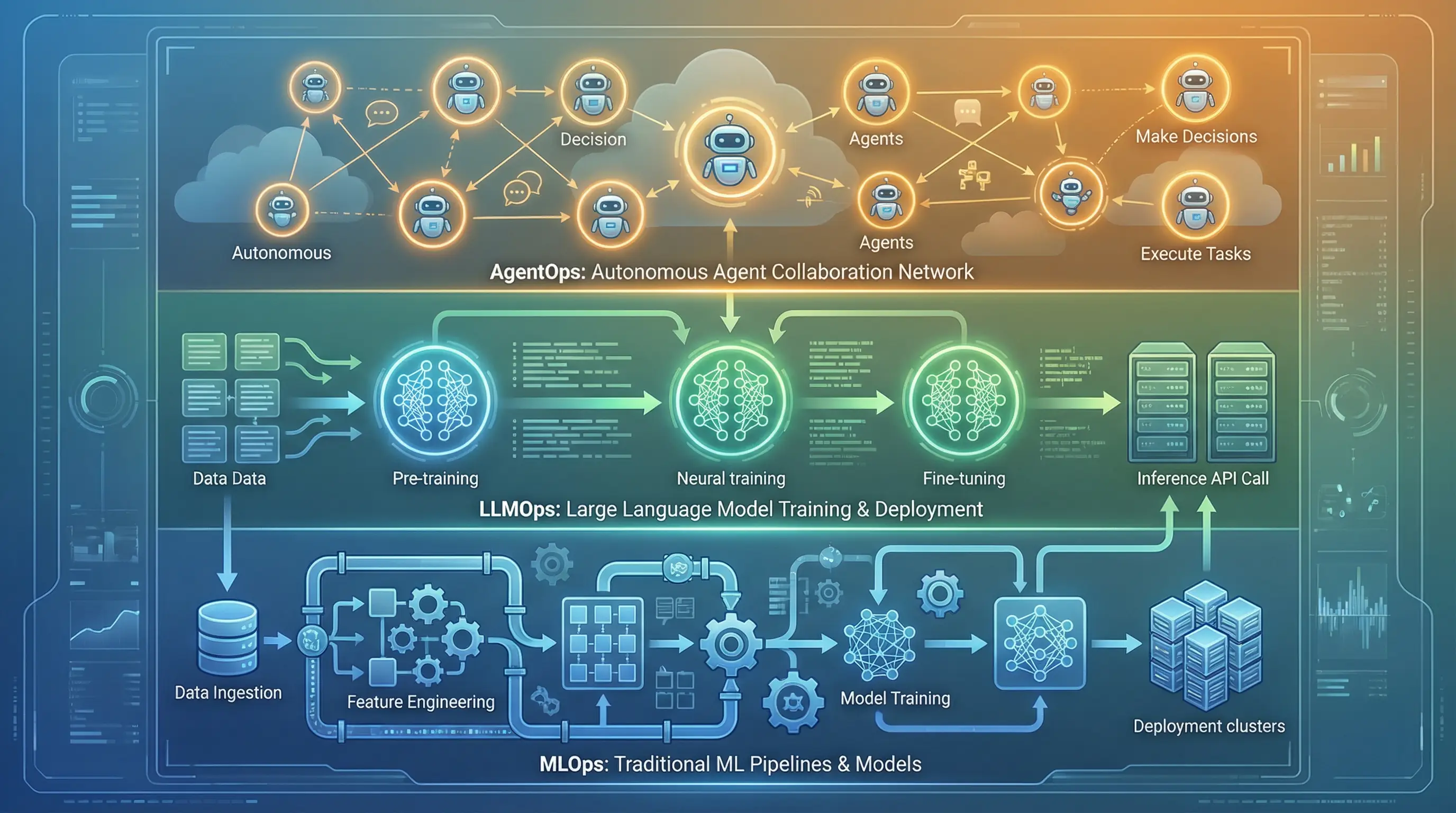
Choosing Your Framework: LangGraph, AutoGen, and CrewAI
Building agents from scratch rarely makes sense in 2026. Multiple frameworks offer production-ready components, but each comes with trade-offs.
LangGraph has emerged as a leading choice for developers who want fine-grained control. Its graph-based approach makes agent workflows explicit and debuggable. Teams can visualize exactly how decisions flow through the system, which helps when things go wrong. The tradeoff is complexity: LangGraph requires more upfront design work than simpler alternatives.
AutoGen from Microsoft offers a more flexible approach, with strong support for multi-agent systems where different agents handle different aspects of complex tasks. This flexibility comes at the cost of harder debugging, as interactions between agents can produce unexpected behaviors that are difficult to trace.
CrewAI provides the most opinionated structure, with clear conventions for how agents should interact. This makes it easier to get started but harder to customize when requirements don’t fit the CrewAI paradigm.
For most organizations, the choice depends on team expertise and specific requirements. Teams with strong software engineering backgrounds often prefer LangGraph’s explicitness. Organizations prioritizing rapid development may favor CrewAI’s conventions. Enterprises building complex multi-agent systems might lean toward AutoGen’s flexibility.
Regardless of framework, success depends less on the tool and more on how it’s used. The same framework can produce reliable production agents or flaky prototypes depending on the engineering practices surrounding it.
Testing Agents: The Forgotten Discipline
Perhaps the biggest gap in most agent development efforts is testing. Traditional software testing approaches don’t translate well to agentic systems.
Unit tests verify specific functions. Agents combine multiple functions in ways that create emergent behaviors. Testing individual components tells you little about how the agent behaves end-to-end.
Integration testing helps but faces limits. You can test how the agent interacts with your APIs, but you can’t anticipate every possible user input or system state it will encounter.
The solution involves a combination of approaches. Deterministic testing covers the happy path and known edge cases. Fuzzing techniques throw random inputs at the agent to expose unexpected failure modes. Simulation environments let agents operate on synthetic data that mimics production conditions.
Perhaps most importantly, successful teams treat deployment as the beginning of testing, not the end. They build systems that detect agent failures in production, learn from those failures, and improve continuously. The agent that launches is never as good as the agent that results from months of production feedback.
The Governance Challenge
Technical reliability solves only part of the production agent problem. Governance—how organizations control and account for agent behavior—presents separate challenges that often prove more difficult.
When an agent provides incorrect information that causes financial harm, who bears responsibility? Current legal frameworks offer limited guidance. Organizations must establish internal policies that define accountability before deploying agents that could cause real-world harm.
Audit requirements add another layer of complexity. Regulated industries often require detailed logs of decision-making processes. Agents that operate as black boxes won’t satisfy these requirements. Organizations need techniques for making agent reasoning visible and traceable.
Security presents yet another dimension. Agents with access to multiple systems and the ability to take actions create novel attack surfaces. An agent that can read customer data and send emails becomes a valuable target for adversaries.
Addressing these governance challenges requires collaboration between legal, compliance, engineering, and security teams. Technical solutions alone can’t resolve questions that span organizational boundaries.
What Comes Next
The 89% failure rate for AI agents isn’t inevitable. Organizations that succeed share common characteristics: they invest in infrastructure before agents, start with narrow deployments and expand gradually, build robust testing and monitoring, and tackle governance proactively rather than reactively.
The agents that reach production aren’t necessarily more sophisticated than the ones that don’t. They’re built on better foundations, tested more rigorously, and deployed with clearer understanding of what could go wrong.
For organizations still in the proof-of-concept phase, the message is clear: the gap between demo and deployment is real, but bridgeable. It requires accepting that agent development differs fundamentally from traditional software development. The same approaches that work for deterministic systems will fail for autonomous agents.
The future belongs to organizations that master this new discipline. The 11% of agents currently in production represent the leading edge. As best practices disseminate and frameworks mature, that percentage will grow. The question is whether your organization will be part of that growth or remain trapped in proof-of-concept purgatory.
The technology works. The hard part is everything around it: infrastructure, governance, testing, and organizational change. Companies that figure this out will have real AI agents in production. The rest will keep watching vendor demos.